





Oracle Project Resource Management enables enterprises to:
Leverage Single Global Resource Pool
Deploy Resources Collaboratively
Monitor Resource Utilization
Streamline Organization Forecasting
Analyze Resource Demand and Supply
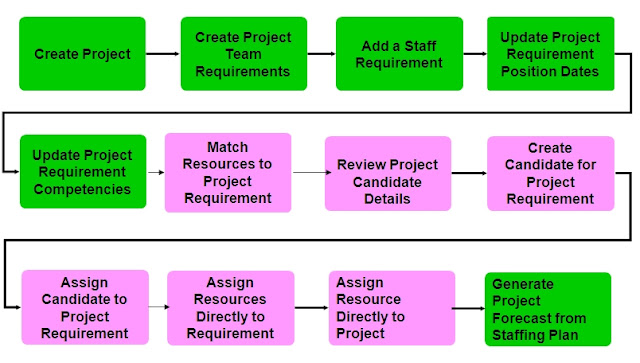
Major Features:
Oracle Project Resource Management enables companies to manage human resource deployment and capacity for project work.
Built using Oracle’s proven self-service model, Oracle Project Resource Management empowers key project stakeholders, such as project managers, resource managers, and staffing managers, to make optimal use of their single most critical asset: their people.
With this application, you can manage project resource needs, profitability and organization utilization by searching for, and locating and deploying most qualified people to your projects across your enterprise.
As a result, you can improve customer and employee satisfaction, maximize resource utilization and profitability, and increase your competitive advantage.
Oracle Project Resource Management is part of the E-Business Suite, an integrated set of applications engineered to work together.
Key Considerations while implementing Project Resource Management:
PJR should be used in very process centric organizations. Value out of the application is made out only when processes are followed and data is properly maintained. Resource search of candidates relies on 3 parameters- Resource availability, Skills Set and Job levels.
Segregation of resources eligible for Staffing - Project Resource Management maintains central resource pool that maintains data about resources availability, skill set, resume, address, job, email, work information, location etc. All the resources in an HR organization need not to be defined in resource pool. This refines the resource search and improve performance of the application.
Integration between Project Resource Management and Project Management - Out of box functionality in Projects module allows integration between Project resource management and Project Management. Integration can be achieved either by Bottom-up approach as well as Top-down approach.
Integration between Oracle Time and Labor and Project Resource Management - Objectives of the Project resource Management and Oracle time and labor totally different as one captures resource planning and other calculates actual. There is no out of box functionality available which integrates these two modules.
Non project centric and small organization - Project Resource Management is not that beneficial for small organizations where there are few projects, non skills based organizations, not much movement of resources across projects or where there are few resources. It is generally used for mid-sized and large-sized organizations.
Leverage Single Global Resource Pool
Deploy Resources Collaboratively
Monitor Resource Utilization
Streamline Organization Forecasting
Analyze Resource Demand and Supply

Major Features:
Oracle Project Resource Management enables companies to manage human resource deployment and capacity for project work.
Built using Oracle’s proven self-service model, Oracle Project Resource Management empowers key project stakeholders, such as project managers, resource managers, and staffing managers, to make optimal use of their single most critical asset: their people.
With this application, you can manage project resource needs, profitability and organization utilization by searching for, and locating and deploying most qualified people to your projects across your enterprise.
As a result, you can improve customer and employee satisfaction, maximize resource utilization and profitability, and increase your competitive advantage.
Oracle Project Resource Management is part of the E-Business Suite, an integrated set of applications engineered to work together.
Key Considerations while implementing Project Resource Management:
PJR should be used in very process centric organizations. Value out of the application is made out only when processes are followed and data is properly maintained. Resource search of candidates relies on 3 parameters- Resource availability, Skills Set and Job levels.
Segregation of resources eligible for Staffing - Project Resource Management maintains central resource pool that maintains data about resources availability, skill set, resume, address, job, email, work information, location etc. All the resources in an HR organization need not to be defined in resource pool. This refines the resource search and improve performance of the application.
Integration between Project Resource Management and Project Management - Out of box functionality in Projects module allows integration between Project resource management and Project Management. Integration can be achieved either by Bottom-up approach as well as Top-down approach.
Integration between Oracle Time and Labor and Project Resource Management - Objectives of the Project resource Management and Oracle time and labor totally different as one captures resource planning and other calculates actual. There is no out of box functionality available which integrates these two modules.
Non project centric and small organization - Project Resource Management is not that beneficial for small organizations where there are few projects, non skills based organizations, not much movement of resources across projects or where there are few resources. It is generally used for mid-sized and large-sized organizations.




.jpg "Teradata –How to secure sensitive information")
.jpg "New Features of Informatica 9 | SRYIT Solutions")





.jpg)





.jpg)
